B2提供免费的10G存储空间, 而且不需要预先设置支付信息例如信用卡认证等。
而且文件上传下载快速
安装
pip install --upgrade b2
配置
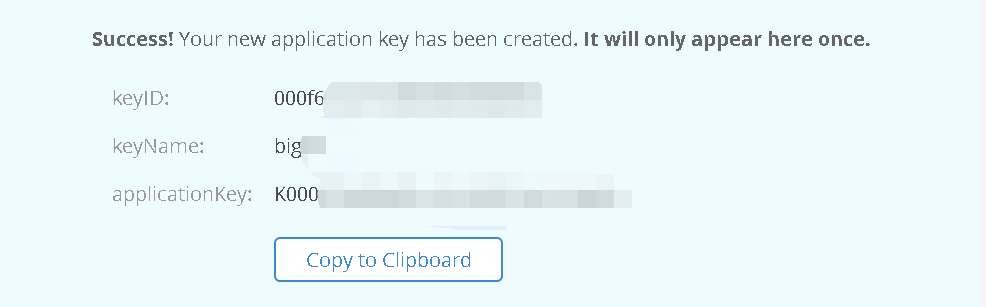
b2 authorize-account [<applicationKeyId>] [<applicationKey>]
上传
b2 upload-file cmp000 "Commander 8.1.0 Installer (x64).zip" cmp_commander_810_x86.zip
Commander 8.1.0 Installer (x64).zip: 100%|███████████████████████████| 835M/835M [06:14<00:00, 2.23MB/s]
URL by file name: https://f000.backblazeb2.com/file/cmp000/cmp_commander_810_x86.zip
URL by fileId: https://f000.backblazeb2.com/b2api/v2/b2_download_file_by_id?fileId=4_z5fb65c33d39d419a79180f12_f20359e5b85eeada6_d20200405_m102029_c000_v0001066_t0051
{
"action": "upload",
"fileId": "4_z5fb65c33d39d419a79180f12_f20359e5b85eeada6_d20200405_m102029_c000_v0001066_t0051",
"fileName": "cmp_commander_810_x86.zip",
"size": 835119744,
"uploadTimestamp": 1586082029000
}

 私有云架构包括4千万行的单体应用,hadoop数据仓库(20PB)和PaaS(2015年)
私有云架构包括4千万行的单体应用,hadoop数据仓库(20PB)和PaaS(2015年)
 数据仓库和PaaS迁移到AWS
数据仓库和PaaS迁移到AWS
 PaaS实施基于EDA架构的改造
PaaS实施基于EDA架构的改造
 PaaS迁移到Fargate
PaaS迁移到Fargate



