Data catalogs solve the problem by tagging fields and data sets with consistent business terms and providing a shopping-type interface that allows the users to find data sets by describing what they are looking for using the business terms that they are used to, and to understand the data in those data sets through tags and descriptions that use business terms.
Data lakes are the do-it-yourself version of a data warehouse, allowing data engineering teams to pick and choose the various metadata, storage, and compute technologies they want to use depending on the needs of their systems. Data lakes are ideal for data teams looking to build a more customized platform, often supported by a handful (or more) of data engineers.
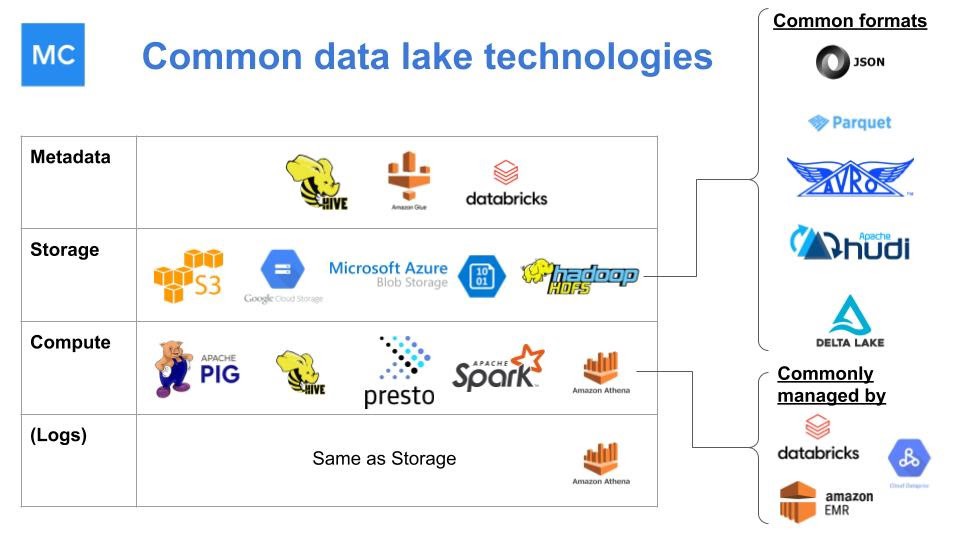
https://towardsdatascience.com/how-to-build-your-data-platform-choosing-a-cloud-data-warehouse
https://www.alibabacloud.com/blog/alibaba-cloud-maxcompute-vs--aws-redshift-azure-sql-data-warehouse