用户代理
mobile devices browsing the web often see a pared-down ver‐ sion of sites, lacking banner ads, Flash, and other distractions. If you try changing your User-Agent to something like the following, you might find that sites get a little easier to scrape!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X)
AppleWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257
Safari/9537.53
scrapy architecture
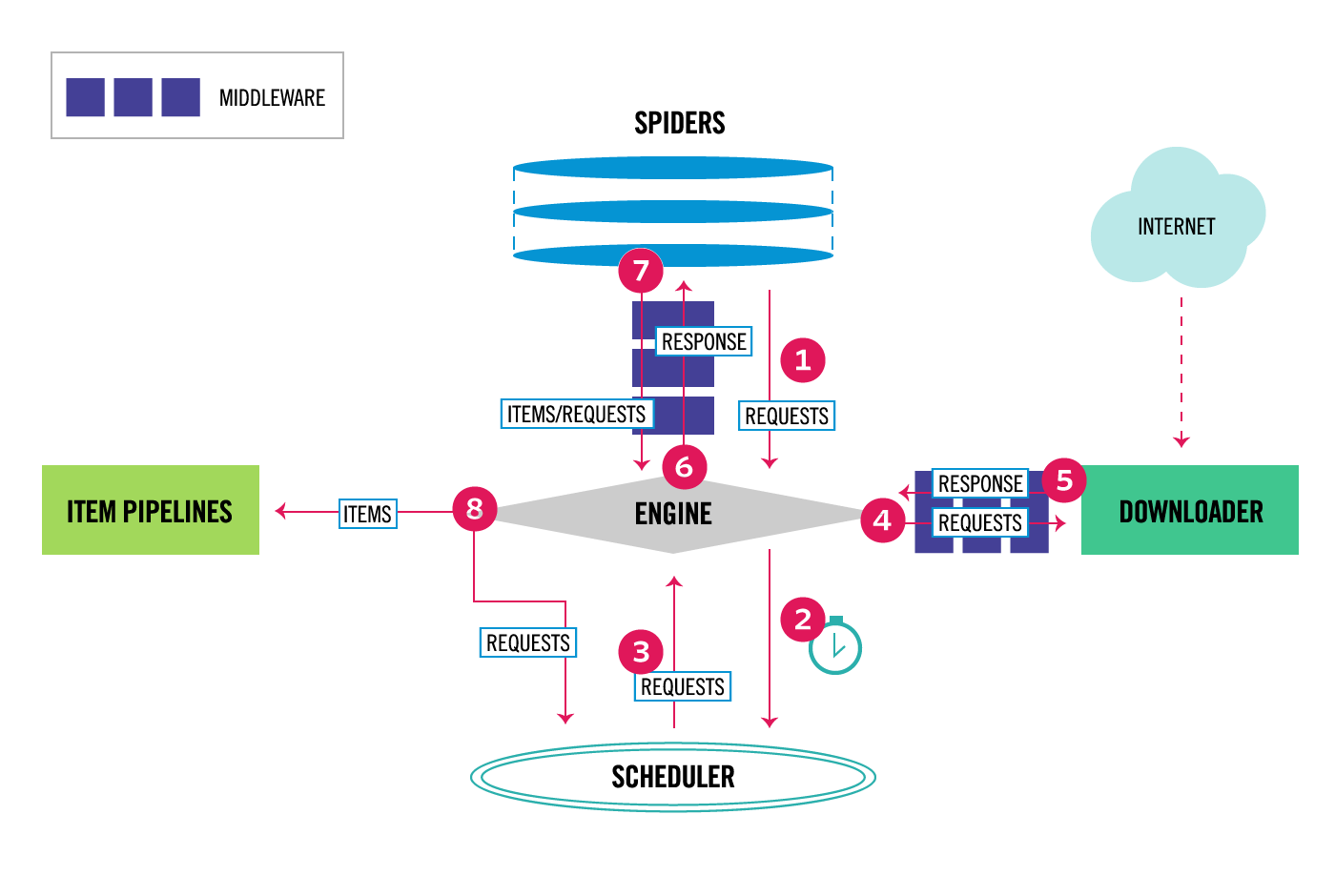
The data flow in Scrapy is controlled by the execution engine, and goes like this:
The Engine gets the initial Requests to crawl from the Spider.
The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
The Scheduler returns the next Requests to the Engine.
The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (see process_request()).
Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (see process_response()).
The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (see process_spider_input()).
The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (see process_spider_output()).
The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.
The process repeats (from step 1) until there are no more requests from the Scheduler.
check cookie
http://www.editthiscookie.com/
CSS vs XPATH
| Goal | CSS | XPath |
|---|---|---|
| All Elements | * | //* |
| All P Elements | p | //p |
| All Child Elements | p > * | //p/* |
| Element By ID | #foo | //*[@id=’foo’] |
| Element By Class | .foo | //*[contains(@class,’foo’)] 1 |
| Element With Attribute | *[title] | //*[@title] |
| First Child of All P | p > *:first-child | //p/*[0] |
| All P with an A child | Not possible | //p[a] |
| Next Element | p + * | //p/following-sibling::*[0] |
CSS selectors are better to use when dealing with classes, IDs and tag names. They are shorter and easier to read
Use CSS Selectors for doing simple queries based on the attributes of the element. CSS Selectors tend to perform better, faster and more reliable than XPath in most browsers