表分区
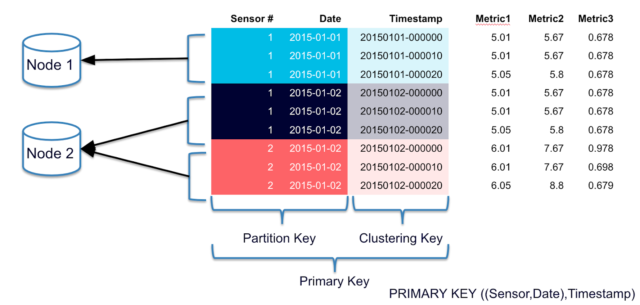
主键=((分区键) + [簇键])
create table kvstor (
k_part_one text,
k_part_two int,
k_clust_one text,
k_clust_two int,
k_clust_three uuid,
data text,
PRIMARY KEY((k_part_one, k_part_two), k_clust_one, k_clust_two, k_clust_three)
);
分区键
分区键决定数据在集群内的分布在哪个分区
簇键
簇建决定数据的在分区内的排列顺序
Cassandra DB 主要缺点
- Cassandra has big issue with Data Read Latency
- Hard to tune-up for both latency and throughput
- Highly depended on Work load and type
- Max 20 % P99 latency drop
- Most memory consumed by storage engine
- To store huge amount of data, JVM is required to manage the memory to clean up garbage collection that is not done by the application but by a language in Cassandra
Cassandra is not recommended if you have following use cases :
- you are not storing volumes of data across racks of clusters.
- if you have a strong requirement for ACID properties.
- if you want to use aggregate function.
- if you are not partitioning your servers.
- if you are application has more read requests than writes.
- if you require strong Consistency.
RocksDB SST 文件在不同 Level 的特性
- L0 层:SST 文件资身是按 Key 排序,但 L0 层的 SST 文件之间是无序的,每个 L0 层的 SST 文件之间会发生 Key Range 的重合,也就是说相同 Key 的数据可能存在于在 L0 层的每一个 SST 文件中。
- L1 ~ Ln 层:多个 L0 层的 SST 文件达到 Compaction 条件后,与若干个 L1 层文件进行 Compaction 后形成新的 L1 层 SST 文件,L1 层 SST 文件之间不会出现 Key Range 的重合,也就是说相同 Key 的数据最多只会存在于 L1 层的一个 SST 文件中(L2 ~ Ln 层同理)。读取数据时,数据可能存在于 Memtable、Block Cache、SST 文件中。
读取操作:
- Point Lookup(点查):先从 Memtable 和 Block Cache 中尝试获取结果,如果没有找到则会按照层级查找 SST 文件。对于 L0 层 SST 文件,先通过 KeyRange 过滤出可能包含此 Key 的 SST 文件再进行查找;再对于 L1~Ln 层的文件进行二分查找定位对应的 SST 文件并进行读取。
- Range Scan:多路归并的思想,返回给用户的 Iterator 由多个 Iterator 组成:每个 Memtable、Immutable Memtable、L0 层 SST 文件、以及多个 L1 ~ Ln 层 SST 文件中构建 Iterator,并以多路归并的方式返回给用户具体的值。
Compaction策略
Compaction 是将多个文件合并成一个文件的过程,在合并过程中会进行相同 Key 的去重,过期 Key 的删除等操作。一次 Compaction 可以简单看作将 N 个文件数据读取后,经过整理再重新写一遍的过程。在这里举两个极端的例子:
- 完全不发生 Compaction:SST 文件只存在于 L0 层,由于 L0 层不保证 SST 之间的 Key Range 不发生重合,所以数据读取需要访问很多 L0 层 SST 文件,在读取性能上会非常差。
- 持续发生 Compaction:假如每生成一个 SST 文件,我们就将它和其他 SST 文件进行 Compaction,那么数据写入的开销则会非常大。
可以看出,Compaction 策略的不同决定了读写放大,也决定了读写的性能,所以一个合理的 Compaction 策略其实是对读写性能的平衡,针对不同场景的需求,我们应该认真考虑其场景所适合的 Compaction 策略。RocksDB 默认提供三种 Compaction 策略,每个策略的触发条件都比较复杂,原理可看对应链接,这里仅描述一下它们的特点:
- Leveled Compaction(默认策略):Compaction 触发频率相对高,读放大低,写放大高
- Universal Compaction:Compaction 触发频率相对低,读放大高,写放大低
- FIFO Compaction:几乎不发生 Compaction,读放大高,写放大几乎没有